Ecuador-Datenportal mit Umweltdaten

Für das RESPECT-Projekt haben wir, basierend auf unserer Toolbox, ein Datenportal gebaut, das verschiedene Klima, Wetter, Umwelt und Beobachungs-Daten verfügbar und analysierbar macht. Zusätzlich haben wir das Datenportal mittels Single-Sign-On an eine bestehende Infrastruktur angebunden.
Highlights
- Integration von Projektdatensätzen (Modelle, Point-of-Interest, Polygonale Flächen)
- Anbindung von externen Daten, z.B. ECMWF, Sentinel-3
- Zugriff über Web-GIS oder Jupyter Notebooks
- Anbindung an Projektinfrastruktur mit SSO
Methodik
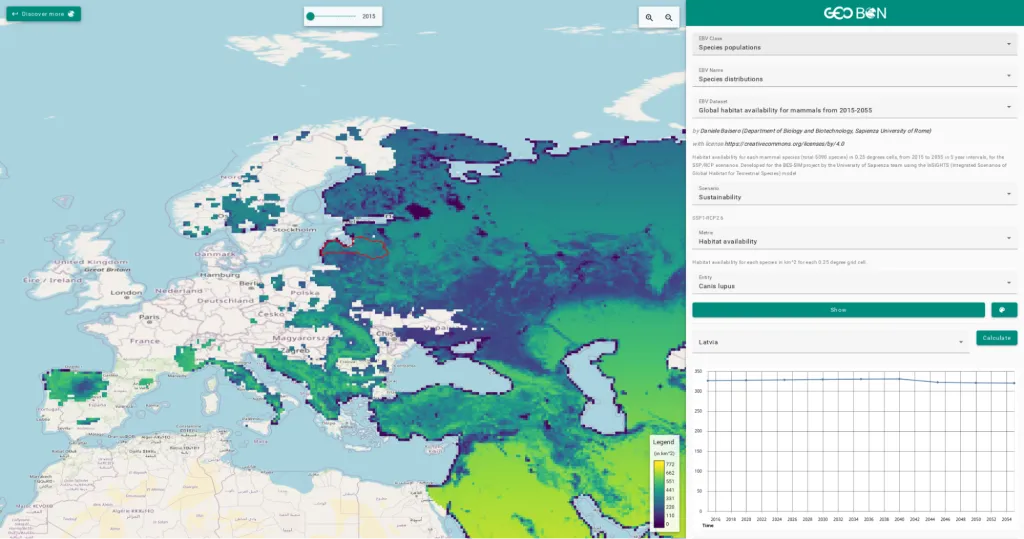
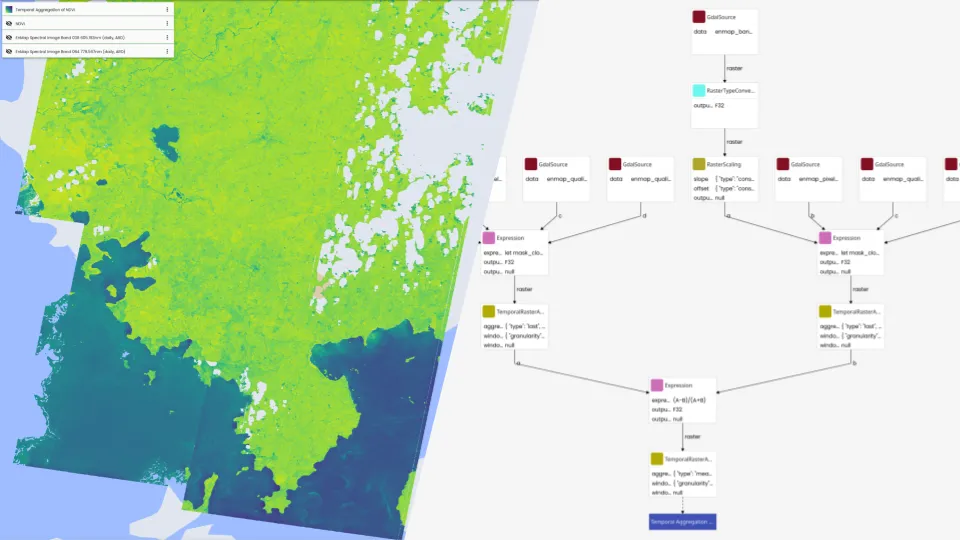
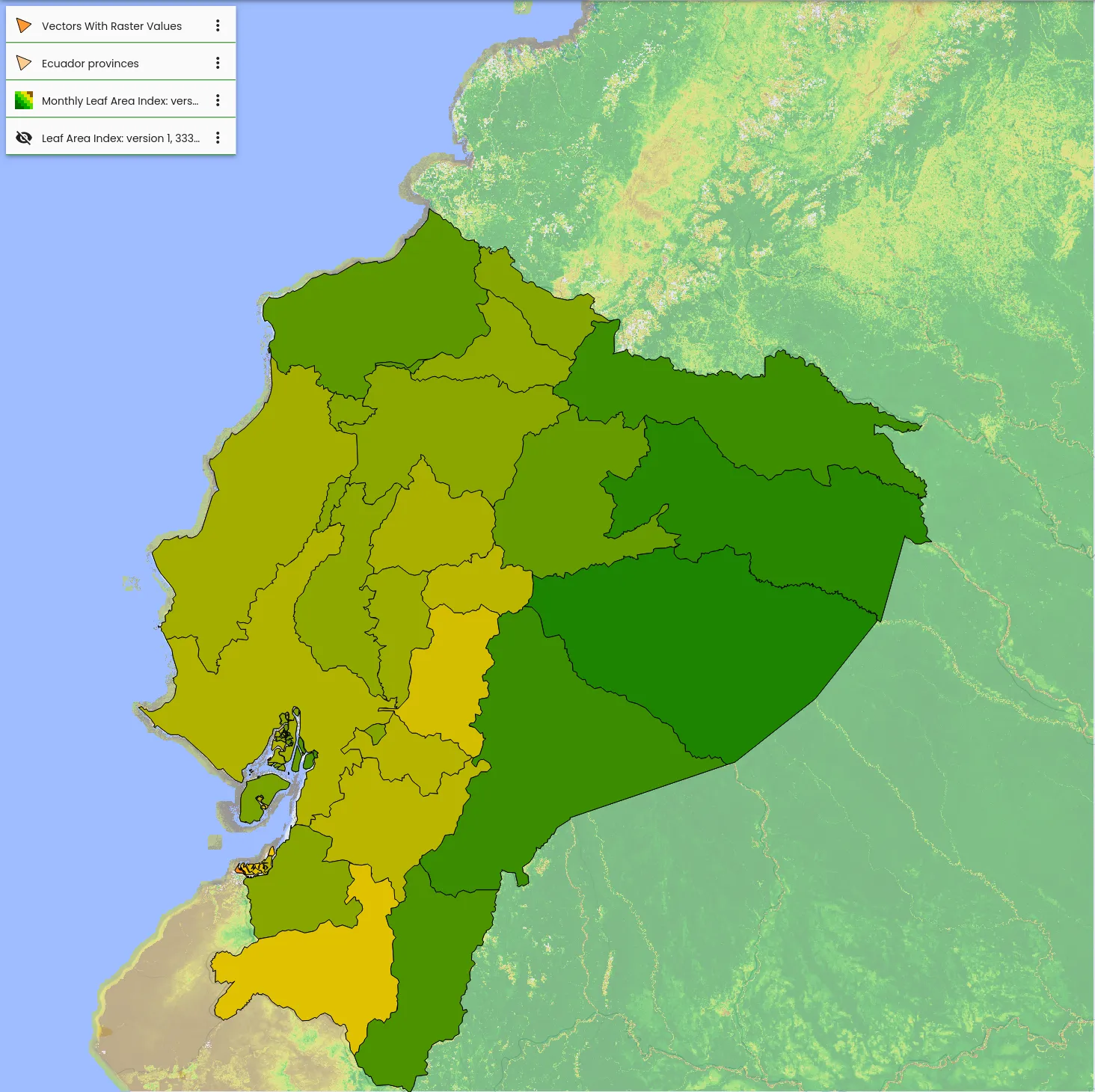
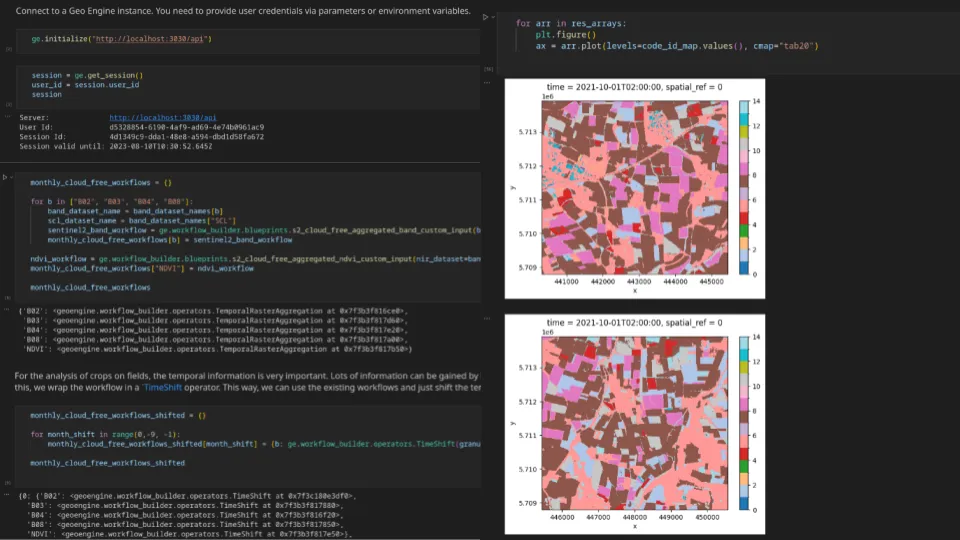
Im RESPECT-Projekt arbeiten Forschende von verschiedenen Universitäten und Instituten zusammen um Umweltveränderungen in den Ökosystemen der Biodiversitäts-Hotspots in Südecuador zu untersuchen. Dazu werden Lösungen sowohl zum Verwalten als auch zum Verarbeiten von Geo-Daten benötigt. Basierend auf der Geo-Engine-Toolbox haben wir ein interaktives Datenportal mit Analysefunktionen aufgesetzt. So können die Forschenden über UI und API auf auf große Datenmengen von Klima- und Wettermodellen zugreifen und diese für ihre Arbeiten nutzen. Um bestehende Nutzer-Accounts und Daten weiterzuverwenden wurde das Datenportal mit unserer Single-Sign-On-Lösung an eine bestehende Projektdatenbank angeknüpft. Im Projekt wird viel mit den genannten Modelldaten, Satellitendaten aber auch lokalen Beobachtungen gearbeitet. Um diese unterschiedlichen Daten zu kombinieren und komplexe Analyse auszuführen, wurden die Daten an die Geo Engine angebunden. Die Forschenden erhalten so Zugriff auf einen Werkzeugkasten von Operatoren. Die Operatoren können zu Workflows kombiniert werden, um Verarbeitungs-Pipelines zu modellieren. Die sonst sehr aufwendige Verarbeitung ist so mit wenig Aufwand einfach umsetzbar. Durch Workflows können auch Verarbeitungsschritte automatisiert werden, sodass diese nicht wiederholt werden müssen. Solche Workflows sind z. B. Satellitendaten von Wolken zu befreien oder Klimamodelldaten an das Gelände im Gebirge anzupassen.