Ecuador data portal with environmental data

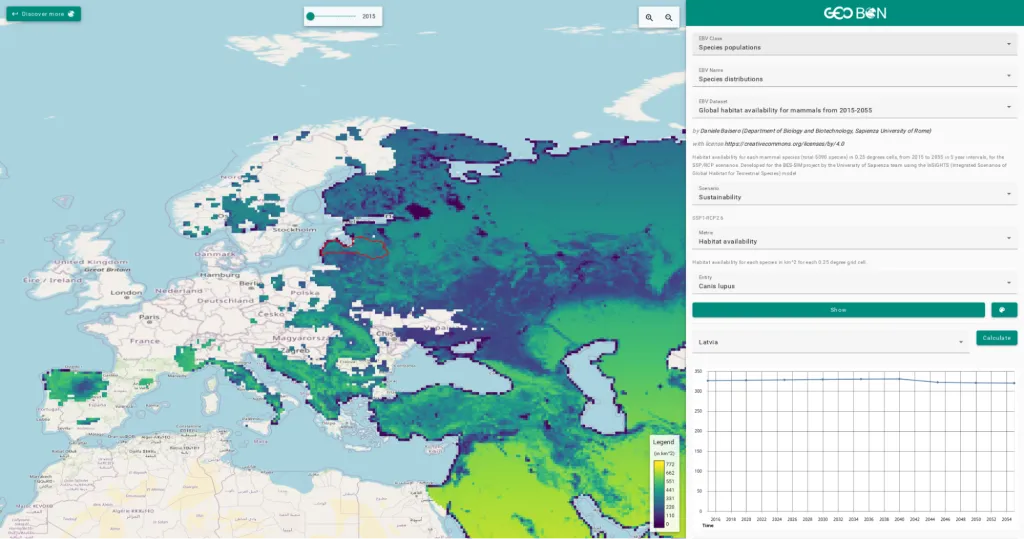
For the RESPECT project, we built a data portal based on our toolbox that makes various climate, weather, environmental and observational data available and analyzable. In addition, we connected the data portal to an existing infrastructure using single sign-on.
Highlights
- Integration of project datasets (models, point-of-interest, polygonal surfaces)
- Connection to external data, e.g. ECMWF, Sentinel-3
- Access via web GIS or Jupyter notebooks
- Connection to project infrastructure with SSO
Methodology
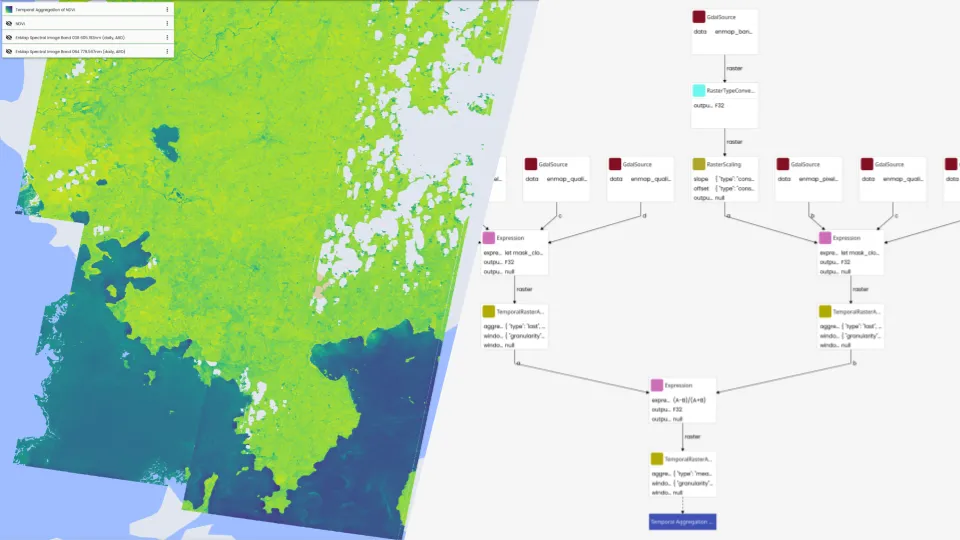
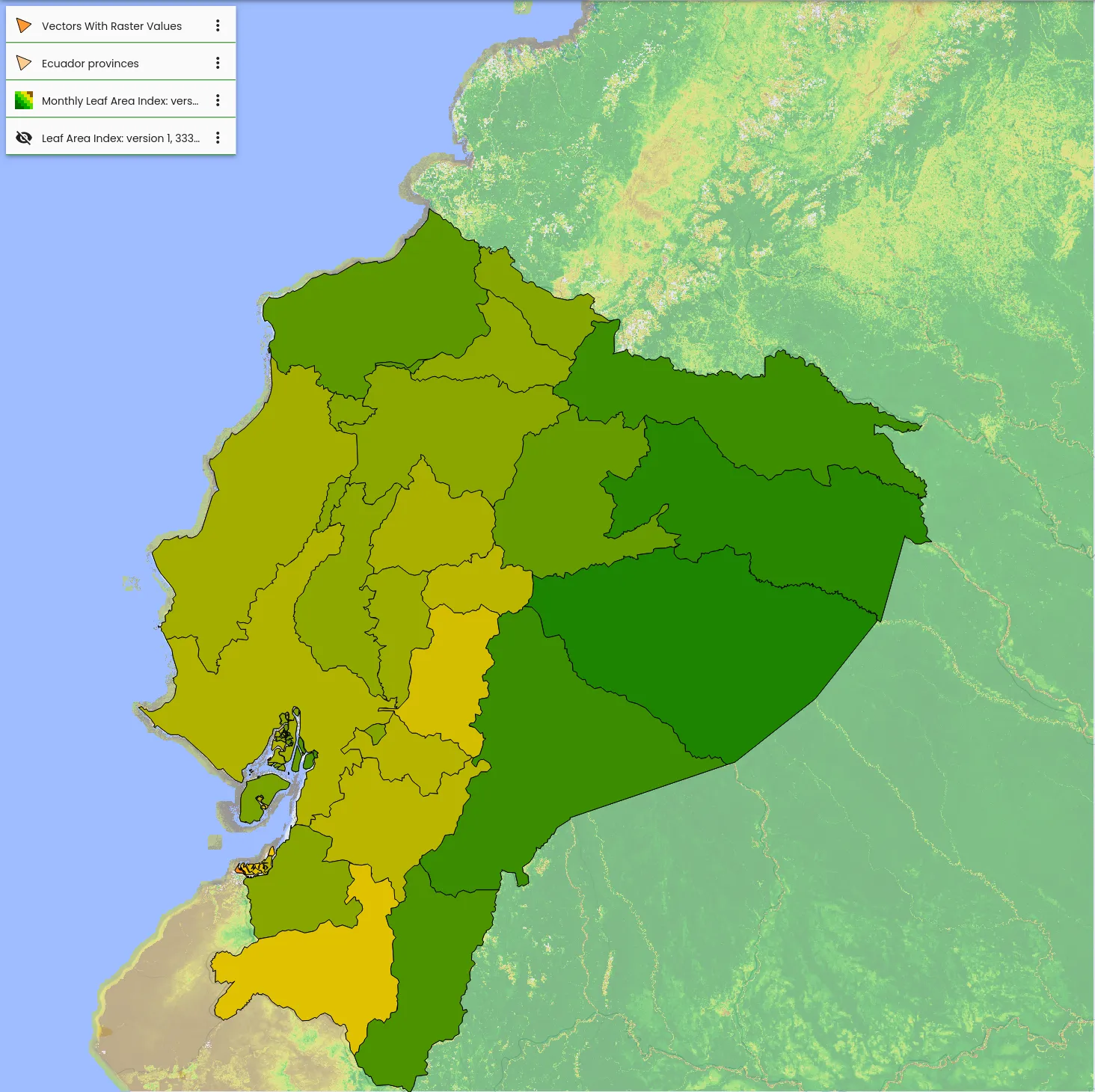
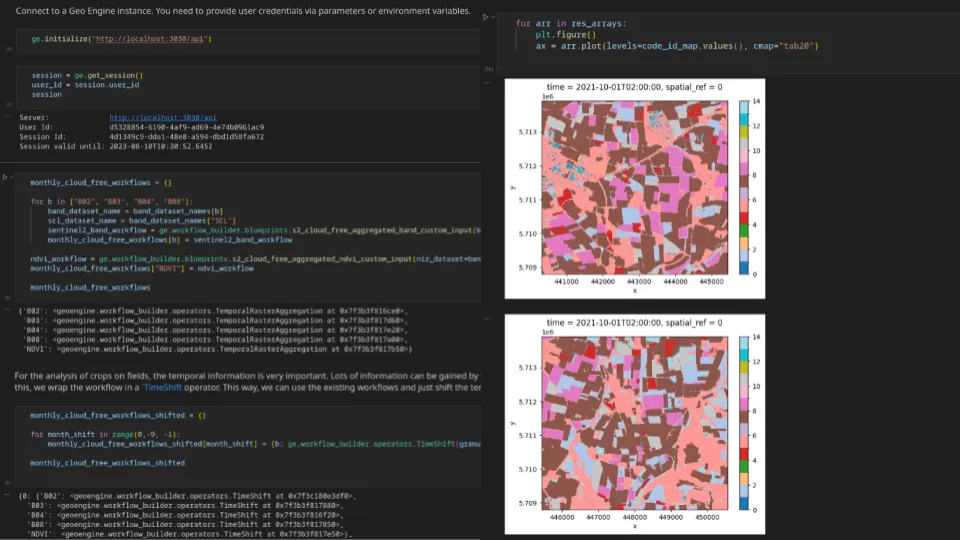
In the RESPECT project, researchers from different universities and institutes are working together to study environmental changes in the ecosystems of biodiversity hotspots in southern Ecuador. This requires solutions for both managing and processing geospatial data. Based on the Geo Engine toolbox, we have set up an interactive data portal with analysis functions. This allows researchers to access large data sets of climate and weather models via UI and API and use them for their work. In order to continue using existing user accounts and data, the data portal was linked to an existing project database with our single sign-on solution. The project works a lot with the mentioned model data, satellite data but also local observations. In order to combine these different data and to perform complex analysis, the data was connected to the Geo Engine. This gives the researchers access to a toolbox of operators. The operators can be combined into workflows to model processing pipelines. Processing that would otherwise be very complex can thus be easily implemented with little effort. Workflows can also be used to automate processing steps so that they do not have to be repeated. Such workflows are, for example, to remove clouds from satellite data or to adapt climate model data to the terrain in the mountains.